
はじめに
CodexやClaude CodeなどのAIコーディング支援を使うと、調査、実装、レビュー、公開作業をかなり速く進められます。
一方で、毎回のチャットで得た知見をその場限りにしてしまうと、次の開発で同じ説明、同じ調査、同じ失敗回避を繰り返すことになります。AIに任せる範囲が広がるほど、使い方そのものを開発資産として残す仕組みが重要になります。
この記事では、Codexに最新ノウハウを調査させ、人間向けのHTMLとエージェント向けのMarkdownへ整理し、別チャットや次の開発で再利用する「ノウハウ循環」の考え方を紹介します。
知見が流れてしまう問題
AI開発で起きやすい問題は、コードの書き方だけではありません。
- うまくいった依頼文が次回に残らない
- 失敗した指示や確認漏れをまた繰り返す
- 最新仕様の確認方法が毎回ばらつく
- チャットが変わると、過去の前提を説明し直す必要がある
- 複数のAIエージェントで作業すると、判断基準がそろわない
この状態では、AIの性能が高くても、運用側の知識が積み上がりません。そこで、開発で得たノウハウを「次のAIが読める形」に戻す仕組みを作ります。
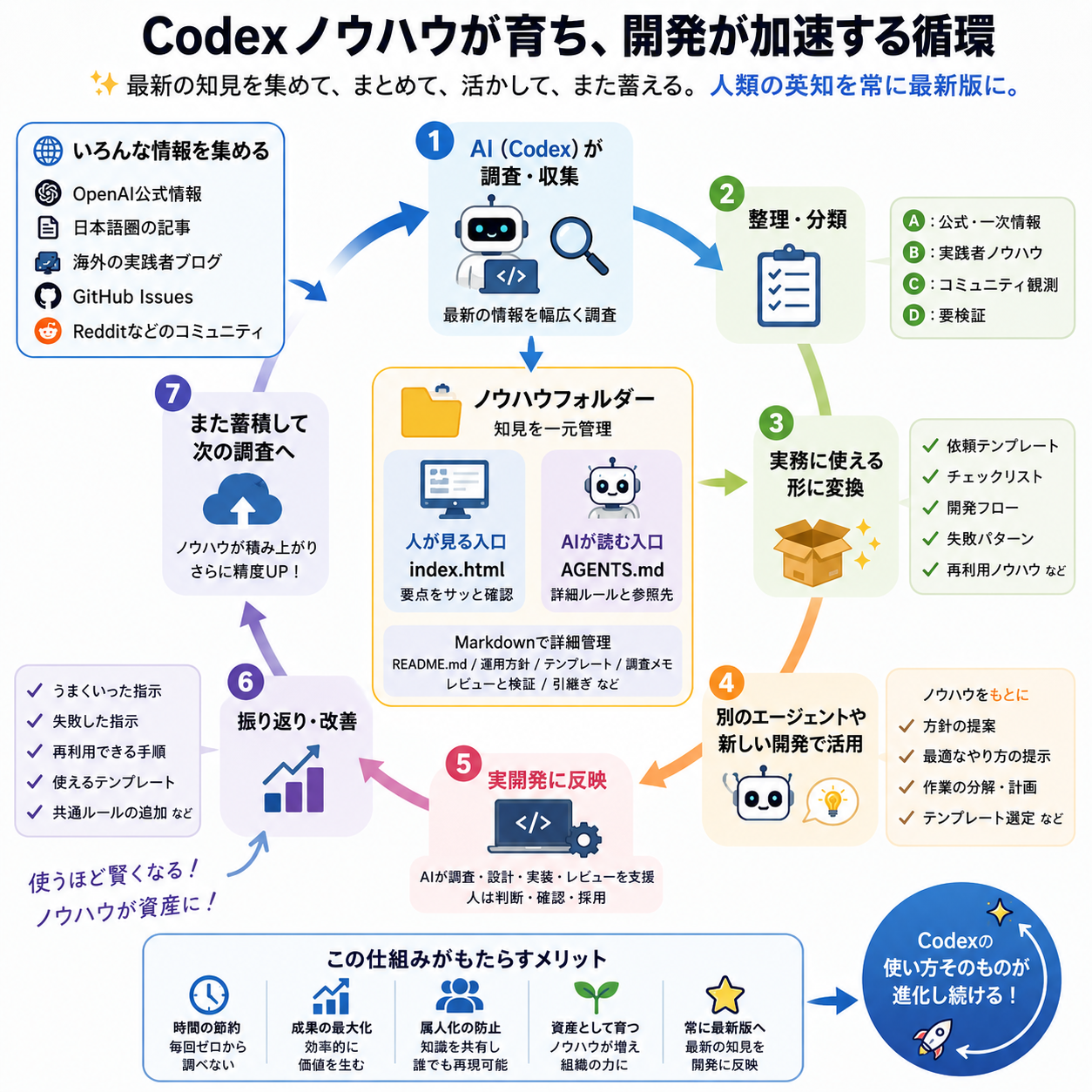
仕組みの全体像
ノウハウ循環は、次の流れで回します。
| 段階 | 内容 | |---|---| | 調査 | 公式情報、実践者記事、GitHub Issues、コミュニティ情報を集める | | 分類 | 情報を信頼度ごとに分け、採用判断をしやすくする | | 変換 | 依頼テンプレート、チェックリスト、検証手順へ落とし込む | | 保存 | 人間向けHTMLとエージェント向けMarkdownへ整理する | | 再利用 | 次の開発前に読ませ、作業方針を提案させる | | 実開発 | 調査、設計、実装、レビュー、公開に反映する | | 振り返り | うまくいった手順や失敗回避を、また知識ベースへ戻す |
ポイントは、調査結果を単なるメモで終わらせないことです。実際の作業で使える依頼文、判断基準、確認リストに変換しておくと、別チャットでも再利用しやすくなります。
情報源を信頼度で分ける
Codexの使い方を改善するときは、情報源の性質を分けて扱います。
| 区分 | 位置づけ | 使い方 | |---|---|---| | A: 公式・一次情報 | 仕様や制約の確認元 | コマンド、API、モデル仕様の判断に使う | | B: 実践者ノウハウ | 現場での使い方 | 作業分解、レビュー観点、プロンプト改善の参考にする | | C: コミュニティ観測 | ハマりどころの検知 | よくある失敗、環境差、注意点を拾う | | D: 要検証 | そのまま採用しない情報 | 実験や公式確認を挟んでから使う |
特にツールの仕様やAPIの挙動は、公式情報を優先します。一方で、開発現場での回し方や失敗パターンは、実践者記事やコミュニティ情報から得られることも多いです。
人間向けHTMLとAI向けMarkdownを分ける
知識ベースには、人間が見る入口とAIが読む入口を分けて置きます。
index.html: 人間がざっと読むための入口。テンプレートやチェックリストを確認しやすくする<Term>AGENTS.md</Term>: CodexなどのAIエージェントが最初に読む運用ルールREADME.md: フォルダー全体の目的、使い方、分類方針- 詳細Markdown: 調査メモ、依頼テンプレート、レビュー観点、公開チェックリスト
人間向けには一覧性やコピーしやすさが重要です。AI向けには、作業前に守るべきルール、参照すべきファイル、完了条件が明確なほうが役立ちます。
この考え方は、AIコーディングでAGENTS.mdを運用ルールとして使う方法 と組み合わせると運用しやすくなります。
開発前に読ませる標準プロンプト
新しい開発を始める前に、次のように依頼します。
Codex効率活用ノウハウのフォルダーを見て、
今回の開発に活かせる作業方針、使えるテンプレート、
Skill化やSubagent活用の候補、検証手順を提案してください。
この依頼を入れると、Codexは単に目の前の実装へ進むのではなく、過去のルールやテンプレートを踏まえて作業計画を出せます。
記事化作業なら 開発資産MarkdownをMDX記事へ変換する作業フロー、公開前チェックなら 技術記事を公開する前のリスクチェックリスト のように、関連する既存ノウハウへ自然につなげられます。
Skill化、Subagent、Automationへ発展させる
最初から完全自動化する必要はありません。まずは手動で回し、型が見えてきた作業から段階的に固定化します。
| 段階 | 向いている作業 | |---|---| | Skill化 | 毎回同じ手順で行う記事化、公開前チェック、用語リンク確認 | | Subagent | 複数記事の候補調査、カテゴリ別レビュー、別観点の品質確認 | | Automation | 定期的なインベントリCSV出力、サイトマップ確認、低リスクなビルド検証 |
たとえば、記事を追加したあとの専門用語リンク確認は MDX記事で専門用語をTermリンク化する運用ルール として切り出しておくと、毎回の確認が安定します。
また、作業開始前に「これから何をするか」をそろえる場合は、Codex作業開始前に進め方をそろえる確認ルール のような固定ルールが役立ちます。
実開発後に戻す情報
開発が終わったあとに戻すべき情報は、完成したコードだけではありません。
- 使いやすかった依頼文
- 途中で発生したエラーと回避手順
- 次回も使える検証コマンド
- 公開前に確認すべきチェックリスト
- 複数エージェントに分けたほうがよかった作業
- 記事化、用語集化、開発事例化できる知見
この振り返りを残すと、次の開発で「前回と同じ説明」を減らせます。案件終了時の観点は 案件終了後に開発資産として残すか判断するレビュー観点 と相性がよいです。
注意点
知識ベースを公開記事へ転用する場合は、内部情報をそのまま出さないようにします。
- ローカルパスは一般化する
- 顧客名、会社名、案件固有の情報は削除または抽象化する
- APIキー、トークン、認証情報は載せない
- 実際の業務データやスクリーンショットは公開前に確認する
- コミュニティ由来の情報は、仕様として断定しない
AIが読むための詳細メモと、読者が読む公開記事は役割が違います。公開用のMDXでは、必要な文脈を補い、機密情報を除き、読者が真似できる粒度に整えます。
まとめ
Codexノウハウ循環の価値は、AIの使い方そのものを開発資産にできることです。
調査、依頼、実装、レビュー、公開、振り返りを毎回少しずつ知識ベースへ戻すと、次のCodexはよりよい前提から作業を始められます。単発のチャットを繰り返すのではなく、使うほど育つ運用にしておくことで、開発速度と品質の両方を上げやすくなります。